使用sklearn进行文本分类(以搜狗用户画像为例)
前言
搜狗用户画像挖掘是2016CCF大数据竞赛的题目,那时候对数据挖掘了解不多,再加上顶着两倍于现在的课程量和课程作业= =,花费大约一半的休息时间用JAVA实现用户分类,但是效果不好,只能达到56%左右(能进复赛的大约66%)。考虑到不能把没精力作为借口,当时就决定怒补基础,苦学py(交易)和skl,借助skl对算法重写和使用python对代码重构,只愿下次参赛不再是一只菜鸟。
回顾文本分类的基本步骤:
数据源获取->数据预处理->特征选择->分类器分类->优化调整->输出结果
本文将按照文本分类的基本方法,一步一步完成训练过程。
1.准备工作+数据源
系统:4核8GB的Windows8.1操作系统
工具:python2.7.3+sklearn+numpy+matplotlib+scipy+jieba
文本编辑器:Sublime Text 3+UltraEdit
搜狗用户画像挖掘复赛数据 :http://pan.baidu.com/s/1jHAmP2u
数据格式为:用户id 年龄 性别 学历 搜索记录若干条(数据均以’\t’划分)
目标:根据已知用户的三个属性和搜索记录,推测只含有搜索记录的用户的三属性
2.数据预处理
因为比赛已经结束,缺少对测试集的评判方法,所以本次实验将训练集(10W数据)按8:2拆分(考虑现实情况,数据集有部分属性缺失的样本,对于这部分样本采用直接舍弃的方法,详细见第二部分数据清洗),即80%的训练集为新的训练集,20%的训练集为新的测试集。
(1)数据清洗
user_tag_query.10W.TRAIN编码方式为GB18030,先将其转换为UTF-8编码,可使用文本编辑器转码,这里使用python对文件转码。
创建PrePareWork.py写入如下代码:
#coding=utf-8
originFile = open("user_tag_query.10W.TRAIN","r")#初始的训练集文件
trainFile = open("train.csv","w+")#清洗后的训练集文件
line = originFile.readline()
i = 0#记录行数
count = 0#记录有效数据数
while line:
i += 1
datas = line.split("\t")
if datas[1] != '0' and datas[2] != '0' and datas[3] != '0':#只记录没有标签缺失的用户
count += 1
context='\t'.join(datas[0:4])+'\t'+'\t'.join(datas[4:]).decode('GB18030').encode('UTF-8')
trainFile.write(context)
line = originFile.readline()
print "records:",count
originFile.close()
这样,我们就得到删除了缺失标签且编码为UTF-8的训练集train.csv:
(2)分词及筛选
中文语句不同于英文,大部分词语紧密相接(英文则全部使用空格隔开单词)。为了继续下一步的特征选择,这里我们需要现对语句切分成词语,并从中删除大量无意义的词语(如‘的’,‘也’,‘是’等等),这些词被称为停用词,即对用户的分类没有太大意义的词语。
但是根据CCF竞赛第一名的想法,实际上在本此实验中的空格、“之”等停用词对分类结果会产生较大影响(学历较高的人对搜索引擎的使用更加娴熟,所以对空格和‘,’的使用次数高于其他人;年龄较低的人对部分小说如玄幻小说情有独钟,搜索记录会包含大量如“之”(网游之XXX小说)的词语;等等)。为了简单起见,这里使用jieba分词后,只保留动词和名词以及统计空格数,删去其他所有词语
创建DelWord.py文件并写入如下代码:
#encoding=utf-8
import jieba
import jieba.posseg
import sys
reload(sys)
sys.setdefaultencoding('utf8')
originFile = open("train.csv","r")#初始的训练集文件
trainFile = open("newTrain.csv","w")#处理后的训练集文件
line = originFile.readline()
usefulWord = ['n','v']#保存词性
q = 0#行数
while line:
if q % 1 == 0:
print 'deal with line:', q
q += 1
inputStr = line.split("\t")
count = 0#记录空格
userSaveWord = []#记录用户的有效单词
context=' '.join(inputStr[0:4])#保存用户标签信息
for i in inputStr[4:]:
words = jieba.posseg.cut(i)
for w in words:
if w.word == ' ':
count += 1
continue
for u in usefulWord:
if w.flag == u:
userSaveWord.append(w.word.encode('UTF-8'))
break
else:
continue
context += ' ' + str(count) + ' ' + ' '.join(userSaveWord[:]) + '\n'
trainFile.write(context)
line = originFile.readline()
分词时间很长,在网上查找相关资料发现windows下不能使用jieba的并行分词模块,所以这里暂不考虑如何更有效的提高分词速度,耐心等待分词完成(这一次可能不会使用全部大约9w的用户,但是可以保存下来下次使用)
3.特征选择
按照基本的文本分类方法,我们只需要统计所有出现过的词汇,并设计一个词袋(保存所有不重复单词),根据词袋求得每个用户的一个关于词语出现次数的向量,所有用户组成为训练集,放入分类器分类预测结果。
虽然在之前数据预处理我们已经删去了大部分的停用词,但是现在是否就已经适合开始分类处理了呢?
删除停用词后的词袋包含词语大约25w,用户数量大约9w,如果将所有词语作为向量维度丢入分类器,那么我们将得到一个25w*9w的巨大稀疏矩阵,不仅处理上会很复杂,还会使结果经度降低
现在先放下这些不管,我们可以开始做些有趣的事(也是做数据挖掘必不可少的一件事————数据分析),我们是否可以根据样本的分布情况,制定相应的对策呢
创建CountInfo.py写入如下代码:
#coding=utf-8
from numpy import *
originFile = open("newTrain.csv","r")#初始的训练集文件
trainFile = open("info.csv","w")#清洗后的训练集文件
age = [0,0,0,0,0,0]
sex = [0,0]
edu = [0,0,0,0,0,0]
line = originFile.readline()
while line:
datas = line.split(" ")
a = datas[1];
s = datas[2];
e = datas[3]
#print a,s,e
age[int(a) - 1] += 1;sex[int(s) - 1] += 1;edu[int(e) - 1] += 1
line = originFile.readline()
trainFile.write(str(age)+"\n")
trainFile.write(str(sex)+"\n")
trainFile.write(str(edu)+"\n")
print "age:",age
print "sex:",sex
print "edu:",edu
运行后将会得到结果,显示不同属性在训练集中每个类别的出现次数:
age: [35965, 24785, 16561, 8967, 2039, 175]
sex: [51540, 36952]
edu: [354, 556, 18708, 27956, 36852, 4066]
[Finished in 4.4s]
通过简单的分析,我们就可以做出一些决定,甚至在不用后面的分类方法的情况下,直接预测结果
样本总数大约9万,现在我们将所有预测属性设为age:1,sex:1,edu:5,预测正确率分别为40%,57%,41%。是不是很惊喜,平均下来已经有50%的准确率了。另外,这个比例可作先验概率用于分析预测结果
接下来,我们回到刚刚的问题,如何解决维数灾难。为了减少词袋中总单词的次数,我们希望可以找到具有代表性的词语,那么只在极少数人中出现的词语是否有代表意义?出现在绝大多数人中的词语是否有代表意义?
这就已经基本涉及到了特征降维理念了,降维处理的方法有很多,这里使用卡方校验的方式,好在sklearn也为我们准备了chi方法。
通过卡方降维后的用户矩阵作为输入,再经过分类器svm(默认参数)的预测就可以得到初步结果了。这里我们先对训练集前1000的数据按8:2划分并测试结果,同时对卡方校验筛选后的维度遍历,找到结果较好的特征维数。新建Classify.py,输入以下代码:
# coding:utf-8
import sys
from numpy import *
import os
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn import svm
import matplotlib.pyplot as plt #导入pyplot子库
reload(sys)
sys.setdefaultencoding('utf8')
def LoadData(l=1000):#返回训练集,标签,词频矩阵,词袋
originFile = open("newtrain.csv","r")#初始的训练集文件
line = originFile.readline()
q = 0
corpus=[]
target=[]
while line and q < l:
tmpdatas = line.split(' ')
datas = " ".join(tmpdatas[5:])
corpus.append(datas)
target.append(tmpdatas[2])
q += 1
line = originFile.readline()
vectorizer = CountVectorizer()#该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j]表示j词在i类文本下的词频
wordcount = vectorizer.fit_transform(corpus)#将文本转为词频矩阵
wordlist = vectorizer.get_feature_names()#获取词袋模型中的所有词语
originfile.close()
return corpus,target,wordcount,wordlist
def chi(wordcount,target,k=200):#返回被选的k个特征构成的用户矩阵"
res = SelectKBest(chi2, k).fit_transform(wordcount.toarray(), target)
return res
def test(l=1000,k=200,j=200,wordCount=None,target=None):#得到预测正确数与错误数
res = chi(wordCount,target,j)
X = res[:-k]
y = target[:-k]
clf = svm.SVC()
clf.fit(X, y)
result = clf.predict(res[-k:])
yes = 0
no = 0
for i in range(len(result)):
if self.target[i + self.allNum - self.testNum] == result[i]:
yes += 1
else:
no += 1
return yes,no
这样我们就完成了对200个用户的性别分类,并根据特征维数的选择情况将正确率反映在图中:
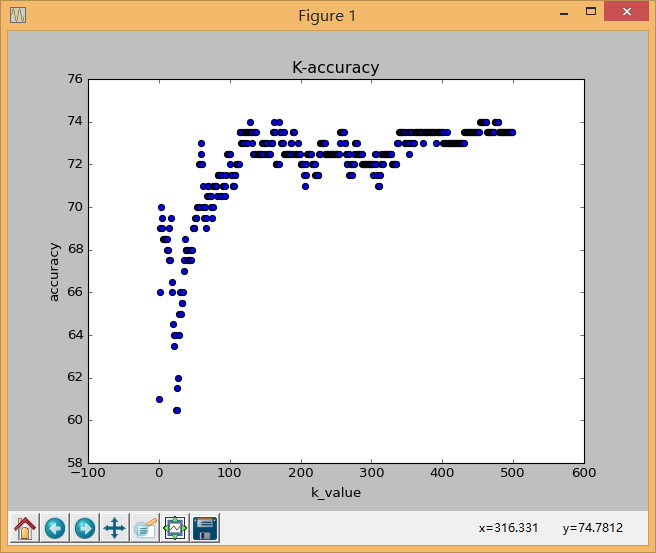
当维度选在450-500时,正确率基本稳定在74%。
通过以上这些步骤,我们就完成了基本的文本分类工作,但是这仅仅是个开始。仍有很多问题需要解决:
1.有多个属性的年龄、学历如何分类?
2.如何对10w用户做文本分类?
3.如何提高分类的准确性?
4.如何整理已完成的代码?
这些问题将在之后的步骤尝试解决
4.分类
其实这部分内容和上面的特征选择合并写到一个函数,通过skl的svm函数,我们就可以直接使用svm分类器而不用自己手工编写。所以这部分将不再描述其他工作。只有一点,对之前已写好的代码进行重构,把以上写好的py代码整合到一个个函数中,并新建main.py写入调用方法。
新建main.py并写入如下代码:
#encoding=utf-8
import PrepareWork as p0
import DelWord as p1
import CountInfo as p2
import Classify as p3
#p0.InitOriginFile("user_tag_query.10W.TRAIN","train.csv")
#p1.DeleteStopWord("train.csv","newTrain.csv")
#p2.CountUserRate("newTrain.csv","info.csv")
这样我们把之前的代码都封装在函数中,并可以在main.py调用。因为这些步骤的结果是产生newTrain.csv和info.csv,而我们已经生成了这些文件,所以在main.py将他们注释掉。
另外,Classify.py每一次都执行了读写文件操作,实际上只需要读取一次,将那些训练样本保存下来就可以了。所以我们将其封装在类中,避免重复操作。重写后的代码不在这里列出,可以访问我的github获取代码
5.优化
有一句话说得很好,分类结果的最大准确程度取决于数据处理和特征选择,而为了达到这个最大准确度,就需要调整分类器参数。
在这个例子中,我决定使用模拟退火算法对SVM的C参数以及特征维数K参数优化。让我们回顾一下之前的工作。
1.切分所有用户的所有语句成为单词,并将这些单词加入词袋
2.使用卡方检验选出K个最具有表现力的单词表示每一个用户
3.将用户中K个单词的出现次数组成向量,输入到SVM分类器
4.使用SVM预测测试集的性别
K值我们已经了解了,就是指选择的特征维数,那么C是什么。
C是SVM的惩罚参数,规定核函数与训练数据的拟合程度,参考sklearn关于svm参数说明文档
K是整数,或许还能使用穷举法求出,但是C是浮点数,又如何选择好的C参数提高分类的准确程度呢?
C的取值问题其实类似于函数求极值。试想我们假设K是固定的,只是为了寻找一个C使得SVM预测结果correct提升,把svm看做一个函数,C的取值就转换为求SVM函数的最大值问题。求函数极值方法有很多,这里我们使用模拟退火算法(可参考这篇文章大白话解析模拟退火算法)
模拟退火思路很简单,例如求函数y=x^5-x^4+x^2极值,步骤为:
1.确定最大步长step(x每次前进或后退的最大值),x取值范围L(x在区间L内取值),取历史最高值时X的取值BestX,y的取值BestScore取最高温度T,取最低温度minT
2.随机选一个x初始值,
3.x按照步长step前进(x+step)或后退(x-step)得到x1
4.比较前进或后退时的y值是否增大,
增大:更变后的x1替换x,同时替换BestScore
减小:一定概率执行‘增大’的相同操作,一定概率拒绝改变x
5.T减小,如果T大于minT则重复3操作,否则停止
6.输出BestX和BestScore
当然模拟退火也可以求得多元函数极值,我们运用以上思想,使用模拟退火算法确定K和C的值,在Classify中添加代码:
def Annealing(self,minTemp=0,minScore=100,KSTEP=5,CSTEP=2):
#搜索的最大范围
KMAX,CMAX=2000,1000 #冷却表参数
MarkovLength = 10000; #马可夫链长度
DecayScale = 0.98 #衰减参数
Temperature = 100 #初始温度
PreK,NextK = 0,0 #prior and next value of x
PreC,NextC = 0.0,0.0 #prior and next value of y
BestK,BestC = 0,0.0 #最终解
PreScore,BestScore,Score = 0.0,0.0,0.0#历史成绩,最好成绩,当前成绩
maxValue = 1000000
#随机选点
PreK = 1#K值
PreC = 0#C值
PreBestK = BestK = PreK
PreBestC = BestC = PreC
yes,no = 0,0
i = 0
#温度过低或分数达到要求时停止
while Temperature > minTemp and BestScore < minscore:
kstep,cstep = maxValue,maxValue
nextk,nextc = PreK + Kstep,PreC + Cstep #如果下一步越界了,重新定步长
while nextk > KMAX or NextK <= 0 or NextC > CMAX or NextC < 0:
Kstep = r.randint(0,KSTEP) - KSTEP / 2
Cstep = CSTEP*(r.random() - 0.5)
NextK,NextC = PreK + Kstep,PreC + Cstep
yes,no,Score = self.CalScore(NextK,NextC)
print "i:",i,"k:",NextK,"c:",NextC,"correct:",Score,"pre:",PreScore,"T:",Temperature,
if Score > PreScore :#比上一个解更好,接受
if Score > BestScore:#比最好解还好,替换
BestScore = Score
BestK = NextK
BestC = NextC
PreK = NextK
PreC = NextC
PreScore = Score
print "accept1"
else:#比上一个解差
change=1000.0 * (Score - PreScore) / Temperature#降低的数值(转化为正数)
#print change,m.exp(change),
if m.exp(change) > r.random():#概率接受较差解
PreK = NextK
PreC = NextC
PreScore = Score
print "accept2"
else:#不接受
print "refuse"
pass
Temperature *= DecayScale
i += 1
return BestK,BestC,BestScore
最后,再改写main.py中的代码:
#encoding=utf-8
import PrepareWork as p0
import DelWord as p1
import CountInfo as p2
import Classify as p3
#p0.InitOriginFile("user_tag_query.10W.TRAIN","train.csv")
#p1.DeleteStopWord("train.csv","newTrain.csv")
#p2.CountUserRate("newTrain.csv","info.csv")
def testAnn():
k,c,score = clf.Annealing(1,80,100,2)
print "Best is:","k=",k,"c=",c,"correct=",score
def testClassify():
global yes,no
for i in range(1,2000):
yes,no = clf.test(i*10)
print "k:",i * 10,"yes:",yes,"no:",no,"correct:",yes * 1.0 / (yes + no)
yes,no = 0,0
allNum,testNum = 2000,400
k,c,score = 1,1.0,0
allNum,testNum = 2000,400
clf=p3.Clf(allNum,testNum)
clf.LoadData(allNum)
testAnn()
以上代码将训练样本扩充至1600,测试样本扩充为400,使用模拟退火求得K和C参数,结果如下:
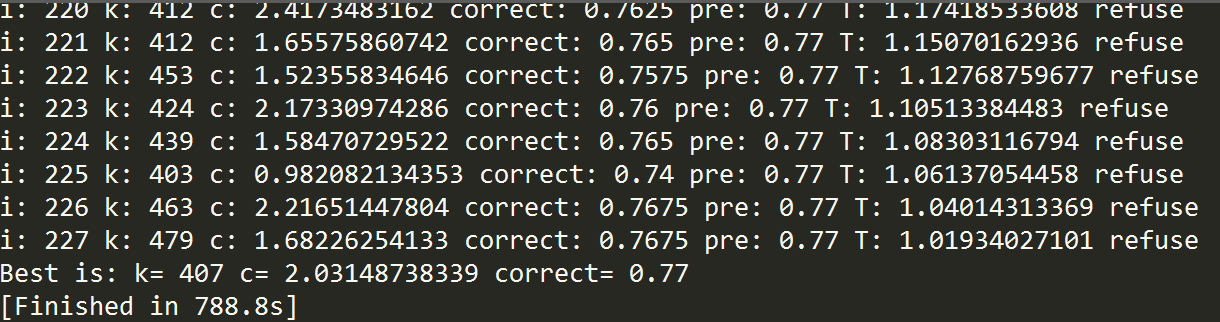
至此,我们就已经完成了较高级的文本二分类工作,同时让代码稍微好看了一些。
这里的学习就告一段落,对于剩下的问题(多分类、大文本分类、精度提升等)将在以后继续做研究和探索。
Thanks~
参考文献:
Scikit-learn:Feature extraction文本特征提取
使用libsvm实现文本分类
TF-IDF与余弦相似性的应用
模拟退火算法例子
sklearn文档索引
卡方检验用于特征选择
github友情链接