2017华为精英挑战赛记录及总结
第一阶段
闲话不能说多。应该是从周三开始着手准备华为竞赛的事情。头一回参加,和图论相关的赛题
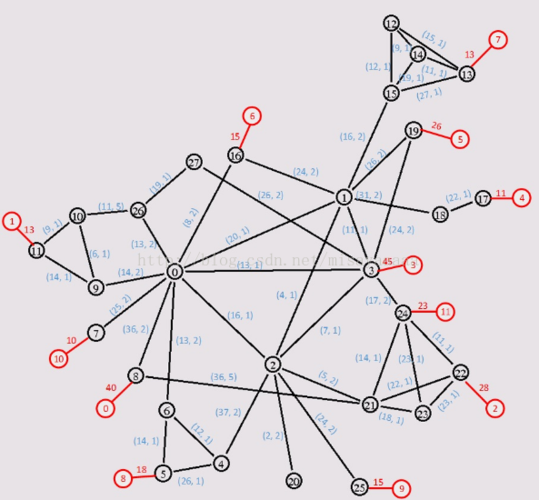
大致就是这么一张图,在红色位置为用户节点,其他位置为网络节点,边权值分别为带宽最大量和带宽的单价费。红色数字表示用户到他直连的网络节点需求的流量。现在我们需要在图中的网络节点找到一些节点作为部署服务器的地方,使得每个用户的流量需求得到满足,同时流量费用+服务器成本为最低。
1.DJS+最大匹配
看上去第一眼感觉不难,立刻有了想法:在用户直连点上部署服务器,将所有服务器看做是一个集合。每一轮对这个集合求最大匹配,匹配的服务器合并为一个服务器,并用新的集合替换旧的集合。在服务器不断合并直到小于某一个数量后,根据所有统计过的成本,选出最小成本作为解答方案。
实际动起手来就发现问题,一个用户可能由多个服务器提供资源,使用这种方法完全无法实现这种解,且合并过程中面临带宽判断和合并判断,逻辑上很麻烦,遂没有实践就直接放弃。
2.双染色体遗传算法+DJS
思考2天后,正好优化算法课在教遗传算法,尝试用遗传写一版实践,将所有服务器为每个用户提供的资源作为一个个体,即设计一个双染色体个体。X为二进制编码,010101…0,X[i]=0代表网络节点不部署服务器,X[i]=1代表部署。Y为整形编码,2,3,1,5,11,…. Y[i][j]代表第i个网络节点给第j个用户的资源供给量。使用DJS计算第i个节点到第j个用户的路径,这样用XY就能完整表示出结果路径的集合。
约束条件:只有X[i]=1时,Y[i][x]才可能赋予非零值,否则全0。另外,Y染色体上的所有资源和必须和用户所有需求资源和相等。这需要在交叉和变异后使用特殊函数对Y染色体做“修补手术”。
交叉:只按X染色体交叉,取个体A和个体B的某个基因片段位置i,交换A.X[i~X.length]与B.X[i~X.length],同时将对应的Y[i][…]全部交换。之后使用修补函数处理数值异常问题。
变异:只对Y染色体变异,取个体A的Y染色体某个基因(对用户供给的资源量)随机增加或减少,变异后使用修补函数处理数值异常问题。
适应性计算:成本低者有更多生存机会。
整流程编码下来后,洋洋洒洒1000行,实际结果惨不忍睹,以200个体为一个种群,繁殖1000代,只能找到不到30组解,且解出的成本为用户直连服务器的两倍以上。所以看来全随机并不靠谱,必须尝试其他办法。
3.遗传算法+最大流最小权算法
尝试中,希望能在竞赛结束前试出结果
第二阶段
历时几天,上交了完整的代码并在测试集更新前挤进了排行榜前32.
具体做法沿用上次提到的遗传算法+最小费用最大流。但是对遗传算法只实现了变异而没有交叉。以服务器的有无决定01序列生成个体,使个体不断变异,并将好的变异结果保存下来覆盖个体。
这从本质上来说是一个非常有局限性的贪心算法。变异相当于试探性的添加加一个服务器或取消一个服务器,如果计算结果较好则变异,否则不变异。几乎100%会进入一个比较差的局部最优解。
然而在测试集更新后居然还能上升到前10,推测很多人的代码在迭代时没有超时判断导致零分。名次现在无关紧要,重要的是如何继续完善遗传算法以及减少寻路时间。
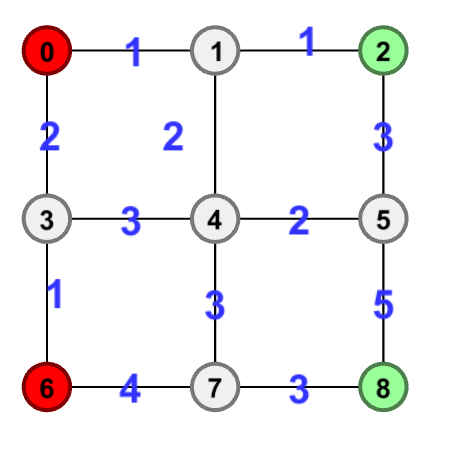
最小费用最大流
在如下一张简单有向图中,红色结点为服务器,绿色节点为用户,边权值为单位带宽的单价,每条边上的总带宽暂不显示。服务器必须传递流量到达用户使用户需求得到满足。
之前走了弯路,寻找到这么一张表格,记录所有服务器到所有用户的流量路径,并每次输出最小路径作为选择(现在假设表中路径满足流量条件。且从上至下,同一服务器的不同路径总花费不断增大,同时后一条路径的选择建立在前一条路径上所有边流量被使用的前提下)
| 服务器->用户 | 完整路径 |
| 0->2 | 0->1->2 |
| 0->2 | 0->1->4->5->2 |
| 0->2 | 0->3->4->5->2 |
| 0->8 | 0->1->4->7->8 |
| 0->8 | 0->1->4->5->8 |
| 0->8 | 0->3->4->7->8 |
| 6->2 | 6->3->4->1->2 |
| 6->2 | 6->3->4->5->2 |
| 6->2 | 6->7->4->1->2 |
| 6->8 | 6->7->8 |
之后不断地在所有路径中找到一条边权最小的边,作为输出路径,满足用户需求,之后减去边上所有已用流量,更新上述表格再次寻找最小权边…直到所有用户得到满足。
n为网络节点数,m为用户节点数,一次DJS+ek为O(n^2),需要在每一轮获得最短边的同时更新表,计算为m*m次,每次要从平均含有m*m条边的表中寻找一条边。这样做的时间复杂度为m^2*(m^2*O(n^2)+m^2),几乎是O(n^6)。在800点的情况下,每进行一次寻路,会花费1s时间。在90s超时的条件下,使用这种做法最多迭代大小为100的种群不到1次(考虑遗传算法种群的生成、变异、交叉、适应度计算)。
之后受到人启发,发现完完全全走了弯路,寻路问题完全可以通过建立超级源点与超级汇点来解决。同样是这张图,将所有服务器连接到一个超级源点,所有用户连到超级汇点,这样问题就变成了单源点->单汇点的最小费用最大流问题。如图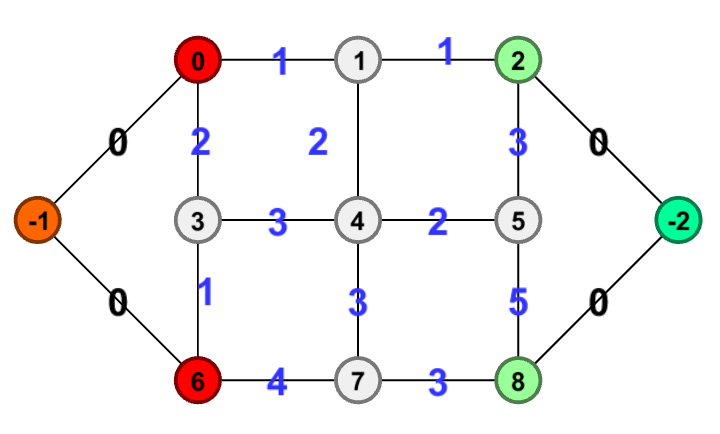
如此一来,只需要更改DJS的起始条件和终止条件,就能在一次寻路算法后找到所有路径,从小权值开始选择,直到满足所有用户需求。复杂度降到了O(n^4)。提交结果参考:
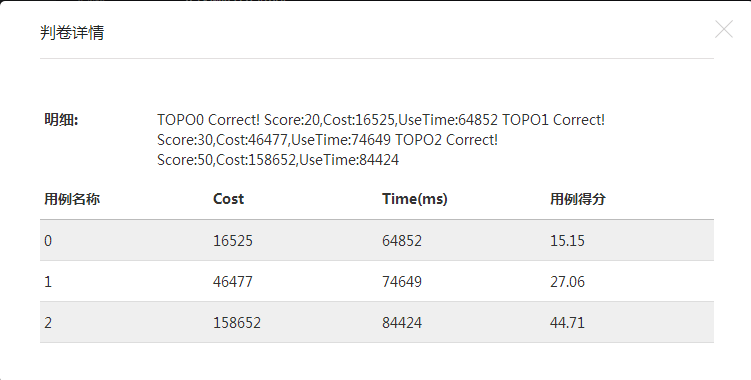
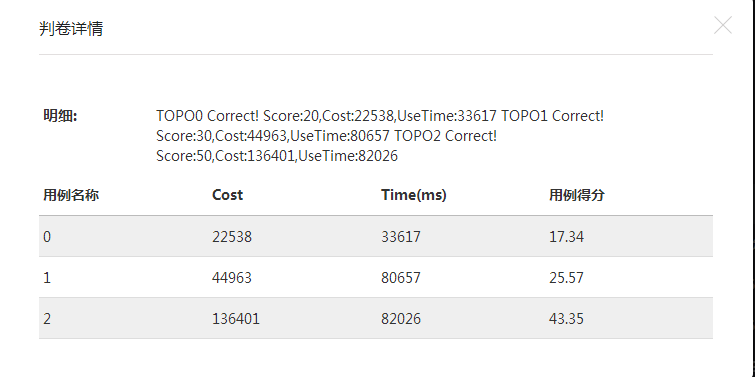
接下来的工作,即继续完成遗传算法,考虑交叉方式和参数设定,尝试使用DJS+Heap提高寻路时间。
第三阶段
本阶段工作:
1.完成遗传算法的交叉、变异、优胜制度编码
2.舍弃DJS算法,改用spfa求最短路径
3.将大部分list替换成int[]以提高运行效率
4.遗传算法的初始化输入由半穷举得出,而不是由直连服务器得出
关于效率对比见下图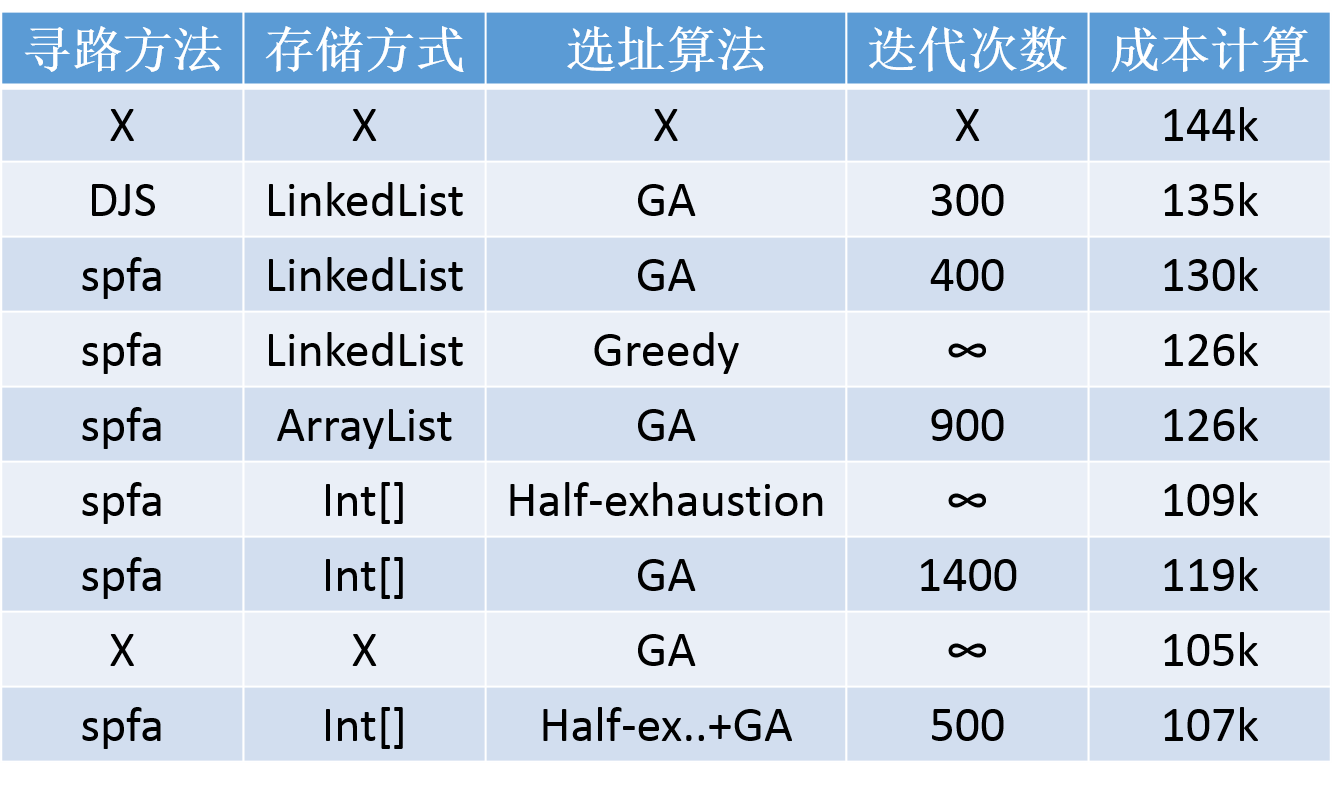
可以明显发现使用spfa+int[]比DJS+list效率超出4倍不止,提高了寻路次数,成本降低更多。而一轮穷举结果+遗传算法综合效果应该是不错的。规定85s内找到了较好解(线下107k,线上110k)。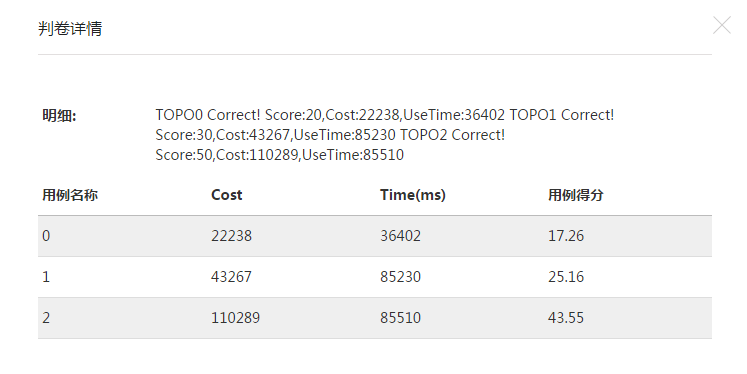
然而依然进不了前30名。。。深感无力,据说前面的人都是在10w以下。
遗传算法在无限时间的情况下,最好跑出了10w5,依然不能到10w以下,所以要不然更换算法,要不然改进迭代方式,以后的工作还是很多,努力思考…
第四阶段
今天是华为经验挑战赛的最后一天,很遗憾没能进入复赛,重新回顾自己这一阵子的付出
3.16 上传了第一份代码,代码没有几行,直接连接服务器,但是连续提交若干次都是0分,感觉很无语连官方文档给的说明都是错的233。
不过最后终于瞎捣鼓出来目录格式,提交成功,很开心!
3.22 学习最小费用最大流,完成遗传算法的变异操作,交叉和选择没写,在更新测试用例后居然排在第6名,怀疑榜上的人可能是没有限制时间导致没有分数
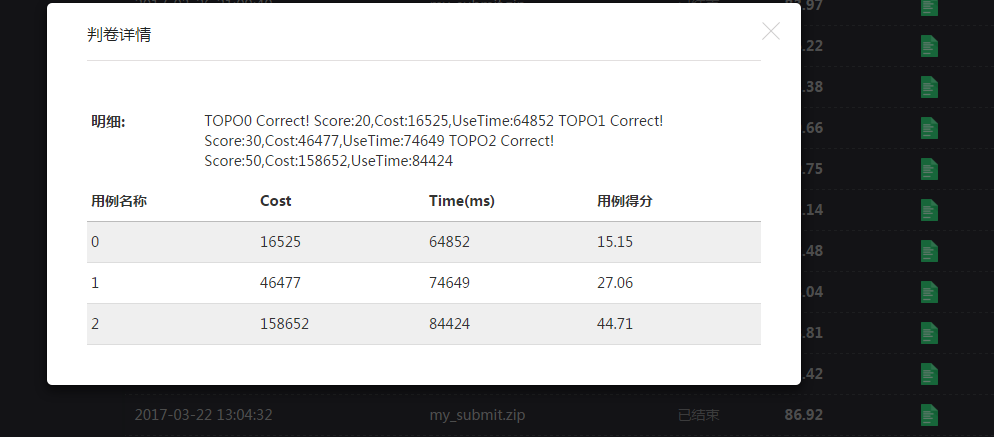
3.25 终于编完了遗传算法的交叉和选择算子,但是效果极差!比直连服务器还要糟糕,苦思冥想不知所措。意外发现群里人说自己的最小费用最大流算法只需要50ms,而自己一轮运算需要200ms以上,效率差4倍,于是一点点更改底层数据结构,终于使成本低于直连服务器
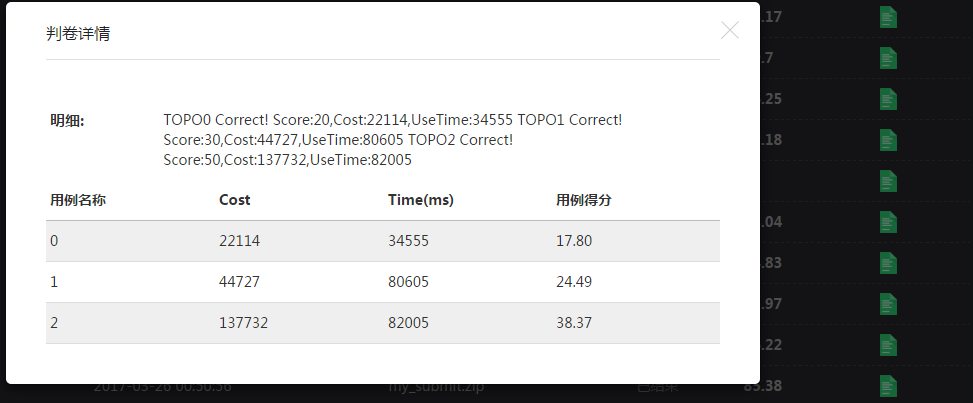
3.26 忽然发现一种神奇的方法,在初始种群前,先直连服务器,然后尝试一个一个删掉服务器,看看成本有没有降低,发现删完以后成本大大降低,比GA迭代以后结果好不知道哪去,干脆直接就这么提交了,初级和中级样例在经过这种预处理后能降低成本大约100~1000,高级没动静,但至少也算提高,勉强排在前30
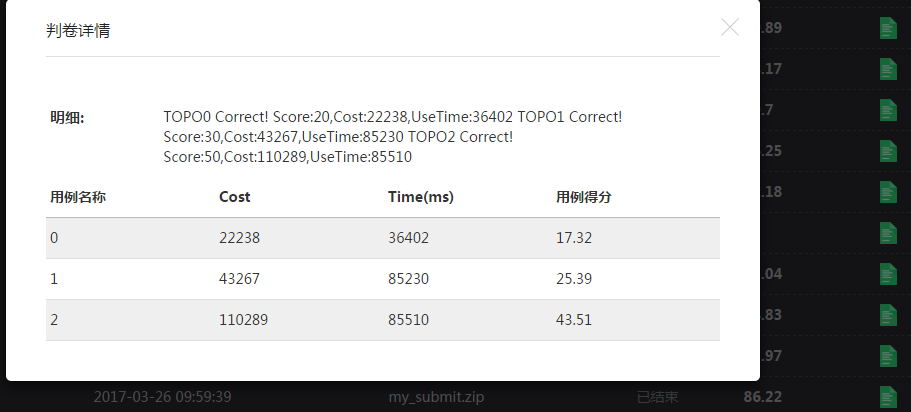
3.31 更新为正式用例,此次更新大大提高了服务器成本。之前排名从30+调到60+,更新后又回到30+,但是依然没有头绪,盲目调参中。
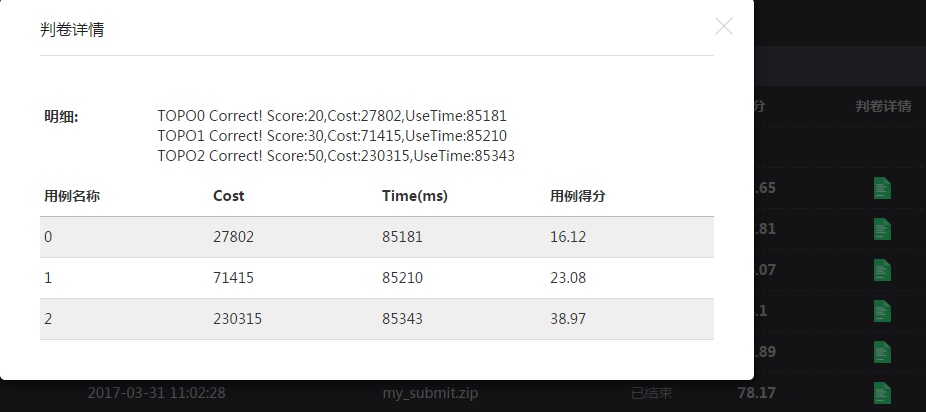
4.4 沉迷于助教和学校项目,再加上努力应付学期作业,算法一直没有改进,期间学了模拟退火算法和粒子群算法,重写一版尝试可惜效果都不好。更悲催的是,在3号早上猛然发现自己的最小费用最大流求错了。。。。。。。。。
另想办法改遗传算法。求得是一个贪心费用流就无所谓了,至少能跑出结果,最后两天看能不能再提高提高。
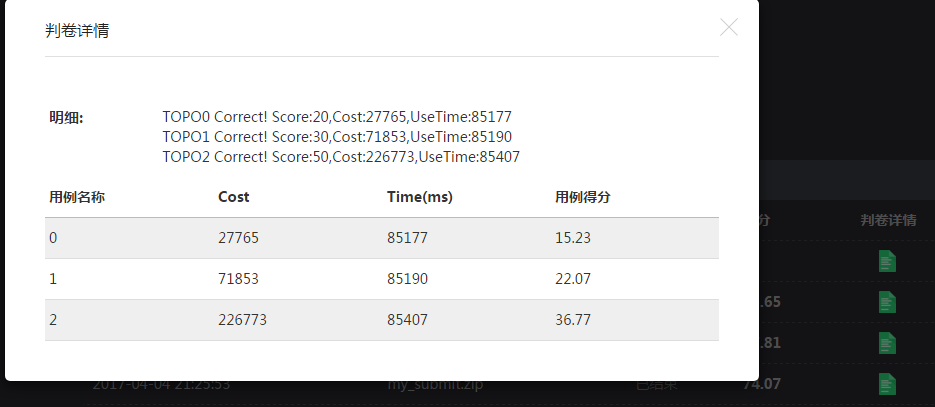
4.5 终于到了最后一天了,尝试更改初始化策略,对初中高三个样例连续运行若干小时,制定了初始化策略,提高了迭代次数,使成绩有小幅提升,但是杯水车薪,与已知的最好解27562、68894、198034相差甚远。最终没能爬上排行榜,结束了两个星期的战斗。
总结:
没能进复赛还是有点可惜,不过这一次基本上把课程上的模拟退火/粒子群算法/遗传算法等全都实践了一遍,收获不少。而且吸取了上次的教训,先是在网上收集相关论文回来看,然后动手开始实践。粗略一数大约30篇论文看过,实际上都没有太大帮助。不得不说,国内的很多水文确实没有帮助,想要做好的效果还是要耐心去读外文文献。另外,不管什么算法需要依据实际情况反复调整,最后才能有好的结果。
技术路线:
1.最大匹配+最短路径,这个想法是在看到题目第一时间想到的。先从用户出发,全部设立服务器,即此时服务器为A1,A2,A3,A4…An,存放在集合S,从S中取出距离最短的两个服务器Ai、Aj,尝试将他们合并,合并的位置为Ai-Aj路径上的某一点(可能要穷举这条路径上的所有点),合并成功则更新集合S,以此往复。
但是这种方法还没尝试就放弃了,考虑最大匹配难求以及合并问题,每一次都如此求得最短路径并穷举节点合并,合并后减去路上流量再次对集合求一个匹配合并,时间复杂度很高也难以实现。
2.双染色体的遗传算法,这种想法参考《改进遗传算法及其在物流配送中心选址优化的应用》,即我们所求的问题分为两部分,一个是选址问题,还有一个是选址后如何分流量的问题。这篇论文的思想是,选址使用遗传算法01编码(即所有的网络节点组成染色体A,染色体每一位基因有值0或1,0表示不放置服务器,1表示放服务器),分配流量也使用遗传算法整形编码(即若染色体A的每一位基因对应染色体B的N位基因,N表示消费者数量。比如用户数1,节点数3,A编码为010,B编码为{(000),(020),(000},这代表第2个网络节点提供给第2个用户资源为2)设置服务器和服务器分配资源都是随机的,通过遗传算法迭代改进。
这种方法让我豁然开朗,想不到居然还能这么算,将两个问题合二为一变成一个问题,简直神奇。然而,其实也应该能想到,对于这次竞赛的图来说约束条件太多,全部随机设置导致最终结果在10000个个体中只有不到30个个体有解,不用说最优解,局部最优都不可能找到。洋洋洒洒的1000+行代码没想清楚就白写了
3.单染色体的遗传算法+最小费用最大流,因为全随机效果很差,又从竞赛群中听来最小费用最大流,能在已知服务器的情况下求得服务器到用户的流量分配方案,这样相当于解决了一个问题,将问题完全变成了选址问题。
这种方法也是用到了最后,但可惜对费用流理解有误,求出的是一个贪心流,不是最优解,这可能导致了最后提交跳过最优解的情况,这是问题之一。另外对遗传算法不能完全按照随机初始种群的方法,这种方法最终得到的局部最优解固然不错但是迭代速度奇慢无比,所以后来我有尝试先遍历服务器尝试删除的方法初始化种群,这样能大大加快迭代速度。
4.K-中心聚类,大致思路为将距离较近的用户划为一类,如果能在这一类用户中找到一个点作为服务器,那么这个解就是较优解
因为对K中心不熟,加之后来事情太多,结果没心思做研究了,包括蚁群算法和拉格朗日松弛法都没能耐心看下去,如果来年再战有机会再次学习。
5.剪枝,虽然只用了一天时间做研究,但是发现种群的初始化是极其重要的,这一点恐怕不仅是遗传算法,其他启发式算法也是如此。通过长时间迭代后,将得到的局部最优解的信息统计,得到节点-服务器设立关系表
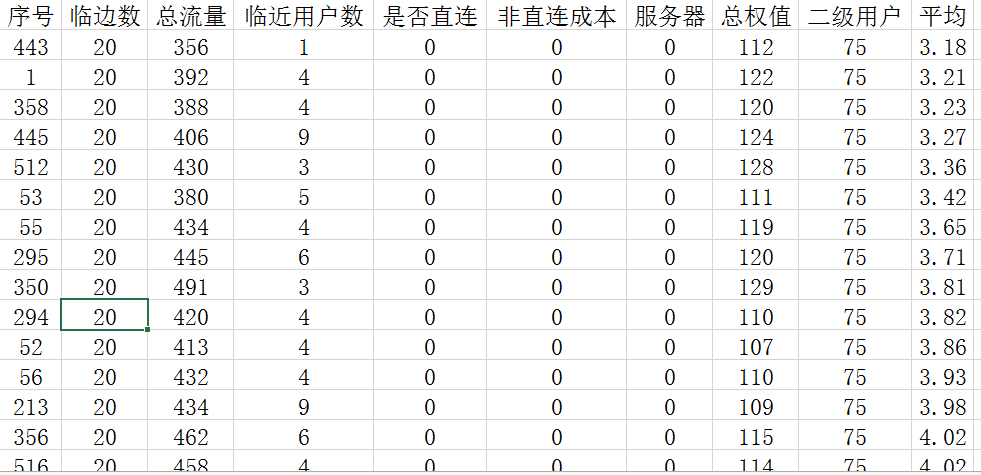
观察发现所有中级的较优解有95%以上在用户直连的节点上架设服务器,而100%的初级用例将服务器架设在直连点上,高级用例大约为85%以上。这样对初级和中级完全只用遍历直连点,相当于减少了超过一半的搜索空间,事实证明最后得到了更好的结果。而不管初中高,统计他们临边数、临近用户数等信息,可以制定一个策略,在随机时避免一些不可能作为服务器的点被随机选为服务器,这也是最后成绩能有小幅提高的原因。所以以后无论做什么研究,都离不开对数据的分析,这一点毋庸置疑。
最后的最后,及时总结及时复盘,做自己感兴趣的事情很重要,继续努力~