K-近邻(KNN)算法及实践
参考书籍《机器学习实战》
K-近邻算法概述
简单来说,k近邻算法采用测量不同特征值之间的距离方法进行分类
k-近邻算法
优点:精度高,对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
适用数据范围:数据型和标称型
工作原理是:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
以电影分类为例,统计电影打斗镜头数和接吻镜头数以及电影评估类型如表2-1:

即使不知道未知电影属于哪种类型,我们也可以通过某种方法计算出来。首先计算未知电影与样本集中其他电影的距离,如表2-2所示。此处暂时不要关心如何计算得到这些距离值,使用Python实现电影分类应用时,会提供具体的计算方法
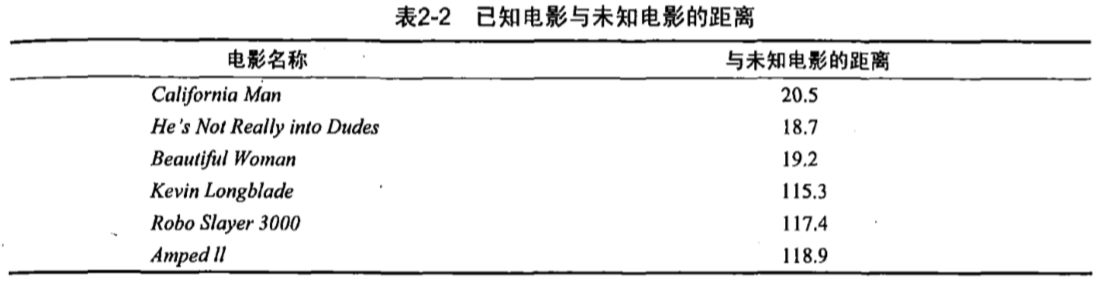
现在我们得到了样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到k个距离最近的电影。假定k=3,则三个最靠近的电影依次是He’s Not Really into Dudes、Beautiful Woman和California Man。k-近邻算法按照距离最近的三部电影的类型,决定未知电影的类型,而这三部电影全是爱情片,因此我们判定未知电影是爱情片。
k-近邻算法的一般流程
(1)收集数据:可以使用任何方法。
(2)准备数据:距离计算所需要的数值,最好是结构化的数据格式。
(3)分析数据:可以使用任何方法。
(4)训练算法:此步驟不适用于k-近邻算法。
(5)测试算法:计算错误率。
(6)使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理。
使用Python实现KNN算法
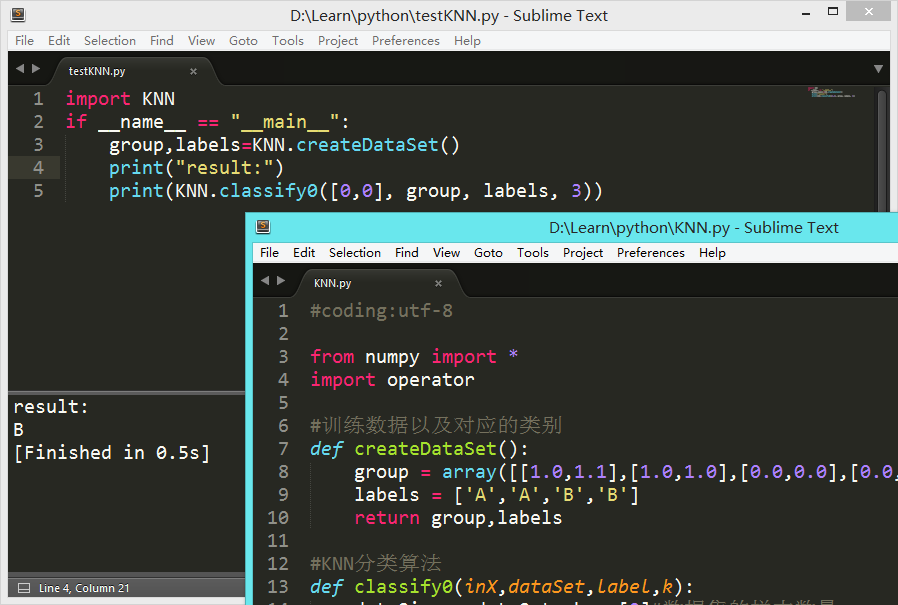
创建文件KNN.py,定义创建数据集函数:
from numpy import *
import operator
# 训练数据以及对应的类别
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0.0,0.0],[0.0,0.1]])
labels = ['A','A','B','B']
return group,labels
定义KNN分类函数:
#KNN分类算法
def classify0(inX,dataSet,label,k):
dataSize = dataSet.shape[0] #数据集的样本数量
###计算欧式距离
diffMat = tile(inX,(dataSize,1)) - dataSet#每个训练样本与测试样本坐标相减
sqDiffMat = diffMat ** 2#相减结果求平方
squareDist = sum(sqDiffMat,axis = 1)#平方相加
dist = squareDist ** 0.5#对平方和开根号
###对距离进行排序
sortedDistIndex = argsort(dist)#argsort()根据元素的值从小到大对元素进行排序,返回下标
classCount = {}#统计近距离的该类别个数
for i in range(k):#统计各类别的次数
voteLabel = label[sortedDistIndex[i]]
classCount[voteLabel] = classCount.get(voteLabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(),
key = operator.itergetter(1),reverse=True)
return sortedClassCount[0][0]#返回标签
inX为输入的测试数据,dataSet为训练集,label是训练集对应的标签,k表示邻近值。
欧氏距离即两点间的直线距离,例如(0,0)与(3,4)距离为sqrt(3^2+4^2)=5
之后使用
KNN.classify0([0,0], group, labels, 3)
验证结果
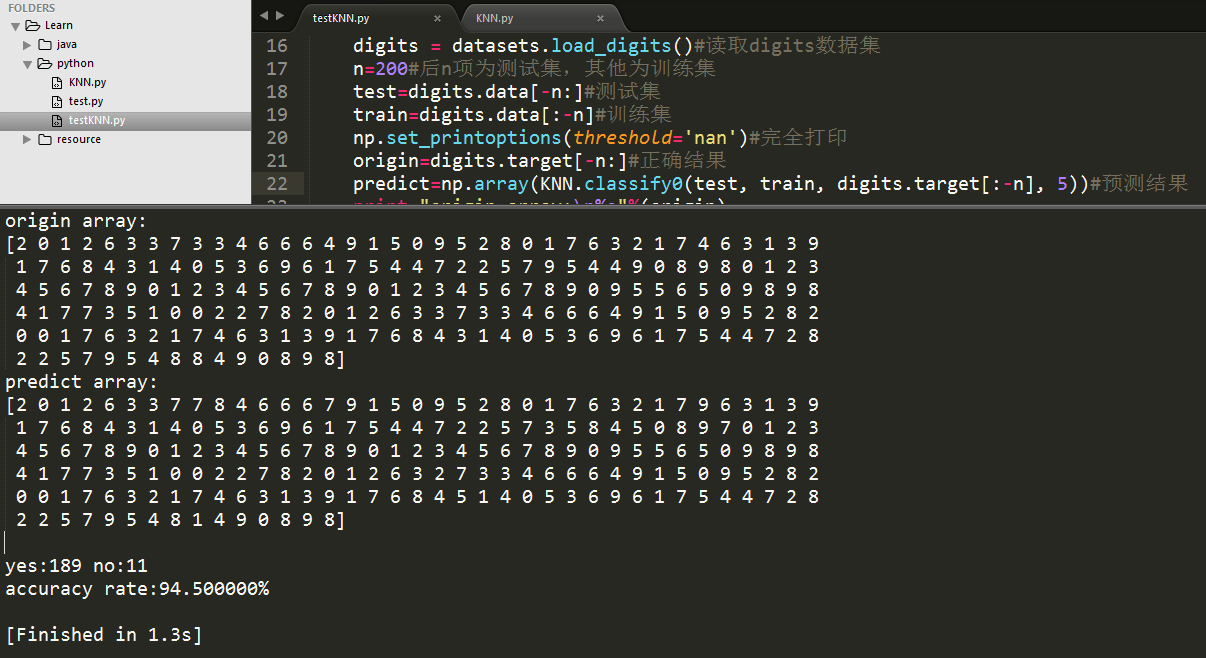
上一次做到KNN简单的示例,训练集只有4个数据。这一次使用digits数据集,把1600个数据作为训练集输入,200个数据作为测试集输入,使用KNN预测并尝试调整k值使结果更精确。得到的训练结果如下:
| K值 | 正确数 | 错误数 | 准确率 |
| 1 | 191 | 9 | 95.500000% |
| 2~3 | 190 | 10 | 95.000000% |
| 4 | 191 | 9 | 95.500000% |
| 5 | 189 | 11 | 94.500000% |
| 6 | 191 | 9 | 95.500000% |
| 7 | 188 | 12 | 94.000000% |
| 8 | 187 | 13 | 93.500000% |
| 9 | 186 | 14 | 93.000000% |
| 10 | 187 | 13 | 93.500000% |
| 11 | 186 | 14 | 93.000000% |
| 12 | 187 | 13 | 93.500000% |
| 13~16 | 186 | 14 | 93.000000% |
| 17~18 | 187 | 13 | 93.500000% |
| 19~20 | 186 | 14 | 93.000000% |
| 30 | 186 | 14 | 93.000000% |
| 50 | 183 | 17 | 91.500000% |
| 100 | 180 | 20 | 90.000000% |
K取值2~6时,准确率达到95以上,超过20以后准确率明显下降。网上对K取值问题讨论不一,这个问题留给之后有大样本输入再思考吧。
测试代码:
KNN.py
#coding:utf-8 from numpy import * import operator #训练数据以及对应的类别 def createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0.0,0.0],[0.0,0.1]]) labels = ['A','A','B','B'] return group,labels#KNN分类算法 def classify0(inX,dataSet,label,k): dataSize = dataSet.shape[0]#数据集的样本数量 result=[]#结果list ###计算欧式距离 for ineachX in inX:#对每个测试元素计算 diffMat = tile(ineachX,(dataSize,1)) - dataSet#每个训练样本与测试样本坐标相减 sqDiffMat = diffMat ** 2#相减结果求平方 squareDist = sum(sqDiffMat,axis = 1)#平方相加 dist = squareDist ** 0.5#对平方和开根号 ###对距离进行排序 sortedDistIndex = argsort(dist)#argsort()根据元素的值从小到大对元素进行排序,返回下标 classCount = {}#统计近距离的该类别个数 for i in range(k):#统计各类别的次数 voteLabel = label[sortedDistIndex[i]] classCount[voteLabel] = classCount.get(voteLabel,0) + 1 sortedClassCount = sorted(classCount.iteritems(), key = operator.itemgetter(1),reverse=True) result.append(sortedClassCount[0][0])#返回标签 return result
testKNN.py
#coding=utf-8 含有中文必须规定编码格式
import KNN
from sklearn import datasets
import numpy as np
def count(a1,a2,yes,no):#统计正确数与错误数
i = 0
while i < a1.size:
if a1[i] != a2[i]:
no += 1
else:
yse += 1
return yes,no
if __name__ == "__main__":
digits = datasets.load_digits()#读取digits数据集
n = 200#后n项为测试集,其他为训练集
test = digits.data[-n:]#测试集
train = digits.data[:-n]#训练集
np.set_printoptions(threshold='nan')#完全打印
origin=digits.target[-n:]#正确结果
predict = np.array(KNN.classify0(test, train, digits.target[:-n], 200))#预测结果
print "origin array:\n%s"%(origin)
print "predict array:\n%s"%(predict)
yes,no = 0,0
yes,no = count(origin,predict,yes,no)
rate = float(100 * yes) / float(yes + no)#正确率
print "\nyes:%d no:%d \naccuracy rate:%f%%\n"%(yes,no,rate)
运行结果: