sklearn学习
1.前言
正值寒假时期,借此机会学习sklearn,同时记录自己的学习经历,以便将来复习。
Scikit-learn学习必要条件:
Python(> = 2.6或> = 3.3),
NumPy(> = 1.6.1),
SciPy(> = 0.9)。
参考windows下python安装NumPy和SciPy模块
下载地址:
Python:https://www.python.org/
NumPy:http://www.numpy.org/
SciPy:http://www.scipy.org/
Scikit-learn:http://scikit-learn.org/stable/
Matploylib:http://matplotlib.org/
根据自身实际情况,所有文件都能在这里下载:
http://www.lfd.uci.edu/~gohlke/pythonlibs/
系统环境:
Windows:64位 4核 6GB RAM
Python:64位 2.7.13
NumPy:numpy-1.11.3+mkl-cp27-cp27m-win_amd64(注意含有mkl,否则导入sklearn部分包会出错)
SciPy:scipy-0.19.0-cp27-cp27m-win_amd64
Scikit-learn:scikit_learn-0.18.1-cp27-cp27m-win_amd64
Matplotlib:matplotlib-1.5.3-cp27-cp27m-win_amd64
相关教程网上有很多,大致看了下numpy,其他内容等实际用到的时候再针对学习。
2.使用scikit-learn进行机器学习的介绍
翻译自http://scikit-learn.org/stable/tutorial/basic/tutorial.html,内容有删改
章节内容
在本节中介绍在scikit-learn中使用的机器学习词汇,并给出一个简单的学习示例。
机器学习:问题设置
一般来说,学习问题考虑一组n个数据样本,然后尝试预测未知数据的属性。如果每个样本不仅仅是单个数字,并且有例如多维条目(也称为多变量数据),则称其具有若干属性或特征。
我们可以把学习问题划分为几个大的种类:
监督学习:数据带有我们想要预测的附加属性,监督学习包含:
分类:样本属于两个或更多个类,并且我们想从已经标记的数据中学习如何预测未标记数据的类。分类问题的一个例子是手写数字的识别,其中目的是将每个输入向量分配给数量有限的离散类别中的一个。另一种理解分类的方式是将其作为监督学习的离散(而不是连续)形式,一个是让提供的每一个n样本具有有限数量的类别,一个是尝试用正确的类别或分组来标记它们 。
回归:如果期望的输出由一个或多个连续变量组成,则任务称为回归。回归问题的一个例子是鲑鱼的长度作为函数预测年龄和体重。
无监督学习:训练数据由一组没有任何相应目标值的输入向量x组成。问题的目标可以是将数据中发现相似的分组,称为聚类;或者确定在输入空间内的数据的分布,称为密度估计;或者将数据从高维空间下降到2维或3维以便于可视化。
训练集和测试集
机器学习是关于学习已知数据集的一些属性并将它们应用到新数据。这就是为什么在机器学习评估算法的常见做法是将手头的数据分成两组,一组我们称为训练集,我们在其上学习数据属性,一组我们称为测试集,我们测试这些属性。
加载示例数据集
scikit-learn附带了一些标准数据集,例如用于分类的iris数据集和digit数据集以及用于回归的boston house prices数据集。
接下来,使用Python解释器,加载iris和digits数据集:
from sklearn import datasets
iris=datasets.load_iris()
digits=datasets.load_digits()
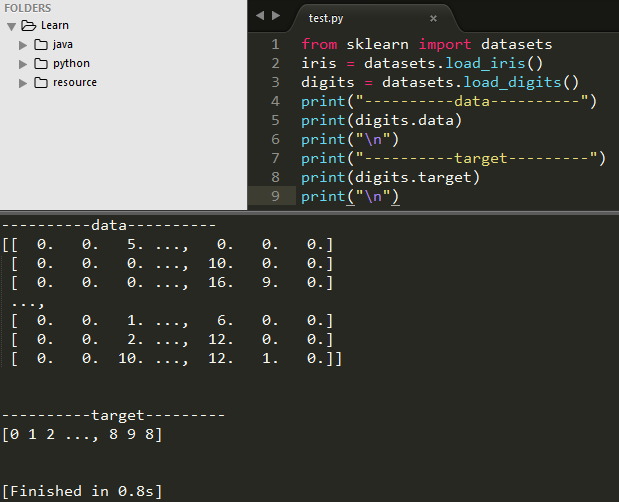
数据集是一个类似字典的对象,它保存所有数据和一些有关数据的元数据。此数据存储在.data成员中,这是一个n_sample,n_feature(n个样本,n个特征)的数组。在有监督的情况下,一个或多个相应变量存储在.target成员中。例如,在使用digit数据集的情况下,digits.data允许访问可用于对数字样本进行分类的特征,digits.target给出了数字数据集的真实标注(该数据属于哪个类别),即对应于我们试图学习的每个数字图像的数字:
digits.data
digits.target
下图为测试输出digits.data和digits.target
数组的shape(形状)属性
尽管原始数据可能具有不同的形状,数据始终是二维数组,且形状为(n_samples,n_features)。考虑digit数据集,每个原始样本是shape(8,8)的图像,并且可以使用以下访问:
digits.images[0]
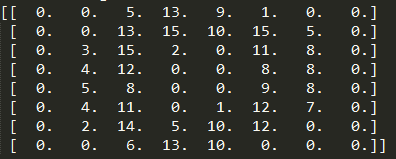
这个样例展示了如何从原始问题开始,通过sklearn塑造数据并使用。
学习及预测
使用digit数据集,给定图像,预测其表示哪个数字。我们给出了10个可能的类(数字0到9)中的每一个的样本,调整评估器以能够预测未知样本所属的类。
在scikit-learn中,分类的评估器是实现方法fit(x,y)和predict(T)的Python对象。
评估器的一个示例是实现支持向量机(SVM)分类的类sklearn.svm.SVC。评估器的构造函数采用模型的参数作为参数,但暂时,我们将把评估器视为一个黑盒:
from sklearn import svm
clf = svm.SVC(gamma=0.001, C=100.)
选择模型的参数
在这个例子中,我们手动设置gamma的值。通过使用诸如网格搜索和交叉验证的工具,可以自动地为参数找到好的值。
创建的评估器实例clf,它是一个分类器,必须从模型中学习,这是通过将我们的训练集传递给fit方法来完成。作为训练集,我们使用除了最后一个数据集之外的所有数据集的图像。用[:-1] Python语法选择这个训练集,它产生一个新数组,其中包含digits.data的最后一个条目:
clf.fit(digits.data[:-1], digits.target[:-1])
<span style="color: #ff0000;">OUTPUT:</span>
SVC(C=100.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma=0.001, kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
现在你可以问分类器在digits数据集中最后一个图像的数字是什么(最后这一项没有用来训练分类器):
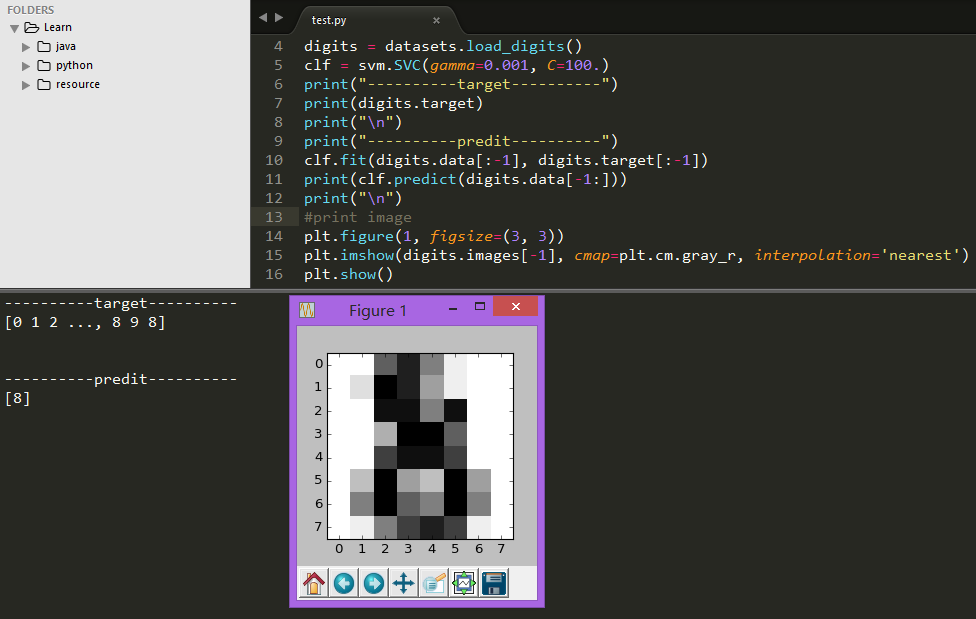
可以看到即使图像分辨率很差,但是分类评估器给出的答案还是令人信服的。
模型持久性
在之后的3.4部分仔细学习,略
默认规则
scikit-learn评估器遵循某些规则,使他们的行为更具预测性。
默认数据类型
除非另有说明,否则输入将被转换为float64
修改和更新参数
在通过sklearn.pipeline.Pipeline.set_params方法构造之后,可以更新评估器的参数。多次调用fit()会覆盖任何以前的fit()的内容。
多类与多标签拟合
当使用多类分类器时,执行的学习和预测任务取决于适合的目标数据的格式
3.针对科学数据处理的统计学习教程
发现网上已经有人翻译官方文献了,在这个基础上稍作修改,让翻译变得适合自己的风格。
官方原文:
http://scikit-learn.org/stable/tutorial/statistical_inference/index.html
翻译原文:
http://www.cnblogs.com/taceywong/p/4570155.html 个人根据实际情况有删改
一、统计学习:scikit-learn中的设置与评估函数对象
(1)数据集
scikit-learn 从二维数组描述的数据中学习信息。他们可以被理解成多维观测数据的列表。如(n,m),n表示样例轴,y表示特征轴。
使用scikit-learn加载一个简单的样例:iris数据集(相同的内容不截图了,上回已经截过)
>>>from sklearn import datasets
>>>iris = datasets.load_iris()
>>>data = iris.data
>>>data.shape
(150, 4)
它有150个iris观测数据构成,每一个样例有四个特征:萼片、花瓣长度、花瓣宽度;具体的信息可以通过iris.DESCR查看。
当数据初始时不是(n样例,n特征)样式时,需要将其预处理以被scikit-learn使用。
通过数字数据集说明数据变形
digits数据集由1797个8×8手写数字图片组成
>>>digits = datasets.load_digits()
>>>digits.images.shape
(1797, 8, 8)
>>> import pylab as pl
>>> pl.imshow(digits.images[-1], cmap=pl.cm.gray_r)
<matplotlib.image.AxesImage object at ...>

在scikit-learn中使用这个数据集,我们需要将其每一个8×8图片转换成长64的特征向量
>>>data = digits.images.reshape((digits.images.shape[0],-1))
(2)估计函数对象
拟合数据:scikit-learn实现的主要API是估计函数。估计函数是用以从数据中学习的对象。它可能是分类、回归、聚类算法,或者提取过滤数据特征的转换器。
一个估计函数带有一个fit方法,以dataset作为参数(一般是个二维数组)
>>>estimator.fit(data)
估计函数对象的参数:每一个估测器对象在实例化或者修改其相应的属性,其参数都会被设置。
>>>estimator = Estimator(param1=1, param2=2)
>>>estimator.param1
1
估测后的参数:
>>>estimator.estimated_param_
二、有监督学习:从高维观察数据预测输出变量
(1)近邻和高维灾难
iris分类:
iris分类是根据花瓣、萼片长度、萼片宽度来识别三种不同类型的iris的分类任务:
>> import numpy as np
>> from sklearn import datasets
>> iris = datasets.load_iris()
>> iris_X = iris.data
>> iris_y = iris.target
>> np.unique(iris_y)
array([0, 1, 2])
最邻近分类器:
近邻也许是最简的分类器:得到一个新的观测数据X-test,从训练集的观测数据中寻找特征最相近的向量。KNN(最近邻)分类示例:
#coding=utf-8 含有中文必须规定编码格式
import numpy as np
from sklearn import datasets
def count(a1,a2,yes,no):#统计正确数与错误数
i=0
while i < a1.size:
if a1[i] != a2[i]:
no += 1
else:
yes += 1
i += 1
return yes,no
def calrate(origin,predict):
print "origin array:\n %s"%(origin)
print "predict array:\n %s"%(predict)
yes,no = 0,0
yes,no = count(origin,predict,yes,no)
rate = float(100 * yes) / float(yes + no) # 正确率
print "\nyes:%d no:%d \naccuracy rate:%f%%\n"%(yes,no,rate)
if __name__ == "__main__":
iris = datasets.load_iris()
iris_X = iris.data
iris_Y = iris.target
np.random.seed(0)
indices = np.random.permutation(len(iris_X))
iris_X_train = iris_X[indices[:-10]]
iris_Y_train = iris_Y[indices[:-10]]
iris_X_test = iris_X[indices[-10:]]
iris_Y_test=iris_Y[indices[-10:]]
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(iris_X_train,iris_Y_train)
predict = knn.predict(iris_X_test)
origin = iris_Y_test
calRate(origin,predict)
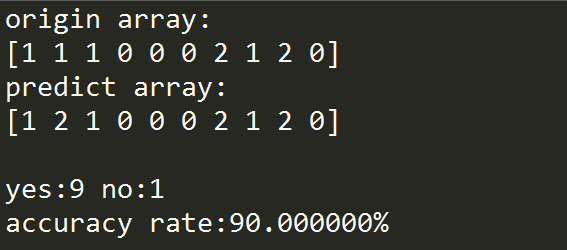
高维灾难(翻译有问题):
为了使估计器有效,需要相邻点之间的距离小于某个值d,这取决于具体问题。在一个维度上,这需要平均n〜1 / d点。在上述k-NN示例的上下文中,如果数据只有一个具有范围从0到1的值的特征,并且具有n个训练观察样本,则新数据将不会比1 / n更远。因此,一旦1 / n小于类间特征变化的规模,则最近邻居判定规则将是有效的。
如果特征数为p,则现在需要n〜1 / d ^ p个点。假设我们在一个维度上需要10个点:现在在P维度中需要10 ^ p个点来铺设[0,1]空间。随着p变大,良好估计量所需的训练点数量呈指数增长。
例如,如果每个点只是单个数字(8字节),则p-20维度中的有效k-NN估计器将需要比整个因特网的当前估计大小更多的训练数据(±1000埃比字节)。
这被称为维度灾难,是机器学习的核心问题。
(2)线性模型:从回归到稀疏性
Diabets数据集(糖尿病数据集)
糖尿病数据集包含442个患者的10个生理特征(年龄,性别、体重、血压)和一年以后疾病级数指标。
diabetes = datasets.load_diabetes()
diabetes_X_train = diabetes.data[:-20]
diabetes_X_test = diabetes.data[-20:]
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
我们的任务是从生理特征预测疾病级数
线性回归
【线性回归】的最简单形式给数据集拟合一个线性模型,主要是通过调整一系列的参数以使得模型的残差平方和尽量小
线性模型:y = βX+b
X:数据
y:目标变量
β:回归系数
b:观测噪声(bias,偏差)
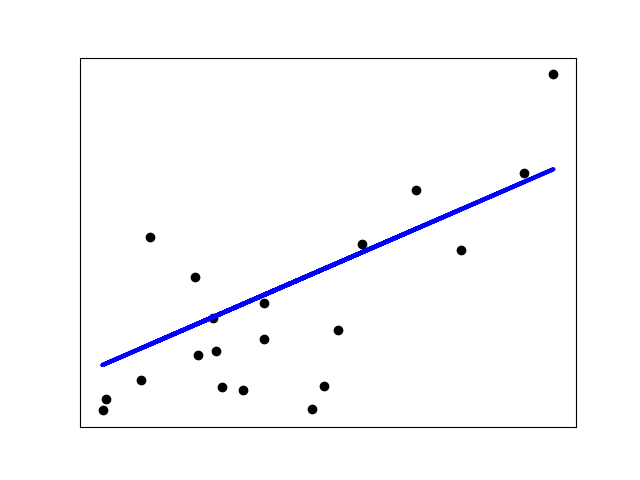
from sklearn import linear_model
regr = linear_model.LinearRegression()
regr.fit(diabetes_X_train, diabetes_y_train)
print(regr.coef_)
np.mean((regr.predict(diabetes_X_test)-diabetes_y_test)**2)#均方误差
print(regr.score(diabetes_X_test, diabetes_y_test))#1代表最佳预测,0表示x与y没有线性关系

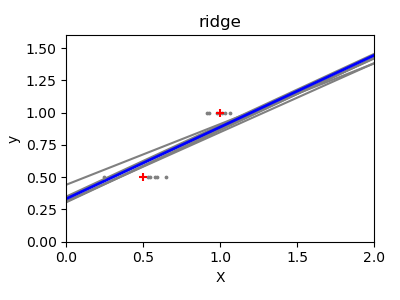
收缩
如果每一维的数据点很少,噪声将会造成很大的偏差影响:
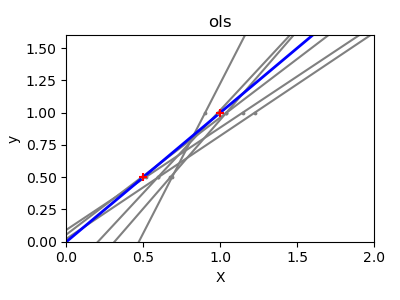
高维统计学习的一个解决方案是将回归系数缩小到0:观测数据中随机选择的两个数据集近似不相关。这被称为岭回归(Ridge Regression):